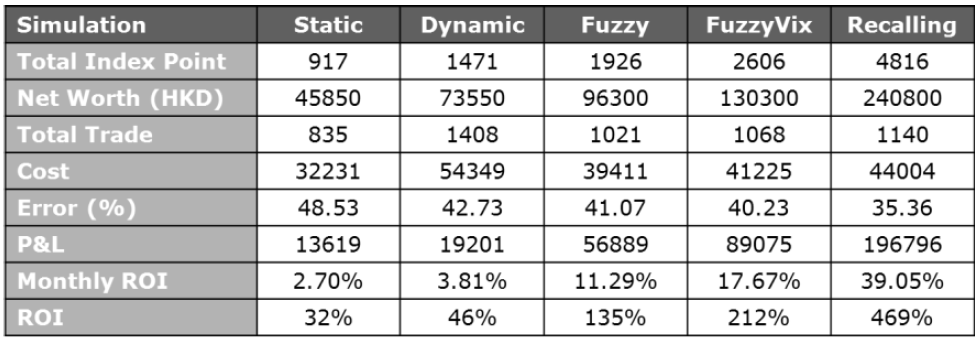
Where do we go from here?
On Thursday, October 3, I impulsively posted an unusual blog entry. It was not typical of the posts on this Alpha Interface blog as it largely contained political content. It suggested a scenario by which the Republican dominated House of Representatives would impeach President Obama. Here is what I wrote:
Can we avoid this scenario? I am afraid that we are heading headlong into a major political crisis. It seems that Republicans are more willing to allow the U.S. to default on its debt obligations than they were to create a shutdown. On October 17, this is likely to force Obama to issue an executive order to the Treasury department to continue issuing bonds to pay existing obligations. In so doing, he will invoke the authority of the U.S. Constitution’s fourteenth amendment that states, “the validity of the public debt of the United States, authorized by law … shall not be questioned.”
Having forced Obama into this position, in order to protect the credit worthiness of the United States, the Republican congress is likely to move toward impeachment, egged on by the most radical anti-Obama elements among them. The Republican grass roots are itching for this event. A quick Google images search on Obama impeachment will yield many, many dozen images (if not hundreds). Because of the power that the extreme right wing now has over the Republican leadership, and the box into which the Republicans have painted themselves, I do not see how this scenario can be avoided.
What are the options? What are the implications?
At the time of my post, twelve days ago, Warren Buffet had just written his opinion that congress “will go right up to the point of extreme idiocy, but we won’t cross it.” My forecast was that the Republicans lacked the wisdom and the discipline to keep us from moving over the precipice.
Then, last week Thursday and Friday, to my surprise the equity markets rallied, buoyed by the rumor that Republicans were moving closer toward capitulation as a result of terrible polling numbers that had come out. They were, it seemed, eager to extract themselves from the situation that they had created. One Republican congresswoman, appointed by the Republican Speaker of the House, John Boehner as a spokesperson, stated that she expected to see an agreement by Monday (yesterday).
Of course, that did not occur. The negotiations between the White House and the House Republicans broke down. Senate Majority Leader, Harry Reid, and his Republican counterpart, Mitch McConnell, have been working on a compromise that, supposedly, was nearing completion. Then, this morning, the news has just come out that the House Republicans, unsatisfied with the concessions likely to be in the Senate compromise, are planning to introduce a bill of their own.
This morning, I heard Jim Cramer on CNBC offer his opinion that the House Republican decision is “bad news” and will ultimately lead to a default. Democratic congressman, Chris Van Holland has also tweeted that the Republican House “plan is not only reckless, it’s tantamount to a default.”
That is where things stand now. It is likely, in my limited mind, that the Republicans see this plan as a winner. If the House approves the measure, and the Senate does nothing (after all one senator, like Ted Cruz, can block the Senate from acting with unanimous consent required in this perilous moment when time is of the essence), the the bill from the House may be the only alternative available to avoid default.
The problem is that such a bill will be unacceptable to Obama and the Democrats. It would, after all, reward the Republicans by cutting back Obamacare provisions, and thus encourage their strategy of extorting concessions they would otherwise not get, as a minority party, only because they threaten to sabotage the entire global economy. From the Democratic perspective, this is equivalent to appeasement of terrorists.
My best estimate, regarding this very fluid situation, is that my original forecast is now relatively on track, even though I had previously withdrawn my prediction. Obama and the Democrats will not approve the resolution by House Republicans. The Senate will be unable to vote on an alternative measure. The U.S. will cross the October 17 deadline and move even closer toward default.
At this point, Obama will be forced to issue emergency executive orders to deal with the situation. I am not sure what those orders will be. He will have public support, but the Republicans will be enraged. The situation can only heat up. Impeachment will be a possibility.
Let me state that I hope none of this occurs. I hope that Warren Buffet’s forecast is correct; except that I strongly agree with the Democratic position that the Republicans should not be rewarded for taking the U.S. economy hostage. I would much rather be maintaining my original focus on the empirical research about financial markets. That, after all, was the whole purpose of this website. However, I confess that the situation is so starkly unique that, to my knowledge, empirical research has little to offer.
At the moment, the equity markets are holding up. The S&P 500 index is near its all-time high. The financial community seems to be completely comfortable with the chaos in Washington. But, the risk as I see it is that the the markets have not given a sufficiently stern warning to the Republicans in congress. The hard right-wingers seem to still believe that they can and will prevail.
My personal belief is that, for the good of the country, the Tea Party right-wingers must be defeated. But, perhaps, this is the wrong battle to fight with the entire global economy at stake. For the sake of the country and the world economy, perhaps the Democrats will support the Republican House resolution. It may lead to greater stability, even if it does encourage further acts of right-wing extortion.