
Bar-Haim and colleagues (2011) from the Hebrew University of Jerusalem downloaded tweets from the StockTwits.com website during two periods: from April 25, 2010, to November 1, 2011, and from December 14, 2010, to February 3, 2011. A total of 340,000 tweets were downloaded and used for their study.
A machine learning system was used to classify the tweets according to different categories of fact (i.e., news, chart pattern, report of a trade entered, report of a trade completed) and opinion (i.e., speculation, chart prediction, recommendation, and sentiment). A variety of algorithms were then employed to determine if some microbloggers were consistently more expert than others in predicting future stock movement.
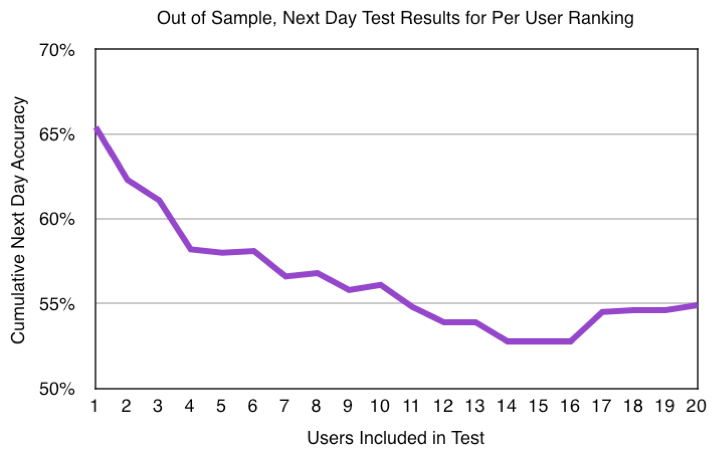
The chart above shows cumulative results for the first twenty users in the “per user” model. This model learned from the development set a separate Support Vector Machine regression model for each individual user, based solely on that user’s tweets. The approach was completely unsupervised machine learning, and required no manually tagged training data or sentiment lexicons.
The results showed that this model achieved good precision for a relatively large number of tweets, and for most of the data points reported in the table the results significantly outperformed the baseline. Overall, these results showed the effectiveness of two machine learning methods for finding experts through unsupervised learning.
While the accuracy level declined as additional users were included, the results were statistically significant for the first eleven users, and again for users seventeen through twenty. Overall, these results illustrate the importance of distinguishing microblogging experts from nonexperts.
The key to discovering the effectiveness of individual microblog posters was to develop unique regression models for each poster, rather than relying on a one-size-fits-all heuristic. It was also important to understand the relevant time frames involved. Another study, for example, found that retail traders responded most favorably to recommendations of message-board posters who had been most accurate during the previous five days.
This post was excerpted from my article on the Future of Financial Forecasting published in the Fall 2013 issue of Foresight: The International Journal of Applied Forecasting.